

Try some data.
Try some data.
Welcome to our newsletter for those who source and consume data.

Said another way, those who need data, find ways to get it, and use it to create value. The engineers, scientists, and analysts — the data people.
Updates will go out roughly bi-weekly (every other week, not twice a week). Most update will focus on customer use cases and case studies with the occasional product update mixed in.
With this being the first post, we’re gonna start with some simple concepts; next week, the deep end.
First, a refresher. mytiki.com is data infrastructure for the legal licensing of consumer data — just keep reading if that doesn’t totally make sense yet.
The short of it is, we work with brands and companies to offer rewards and compensation to their users in-exchange for the legal licensing rights to the user’s data. We aggregate this data across companies to provide powerful unique datasets for you to work with.
We work to make data an on demand asset, just another piece of your stack. Not all too dissimilar to cloud storage or compute. Just define what data you require (a SQL filter) to gain access to both historical records and new records as they stream in.
select * from tiki.transactions
where merchant_name = 'Starbucks'
and transaction_date >= CAST('2023-11-01' as date)Data Delivery: Clean Rooms
No more CSVs, please! We use hosted clean rooms where you can access the data you subscribe to, with automatic updates just like it’s your own database, because it effectively is.
For those unfamiliar with the term, a data clean room is essentially a secure, shared repository as a subset of a larger dataset. Our clean rooms are powered under the covers by Iceberg data lakes. A high-performance format for huge analytic tables compatible with both traditional SQL and modern engines like Spark, Flink, Hive, and more.
Just accept the Shared Resource in AWS and you’re off to the races — at this point it’s just like having your own data lake. Leverage all the AWS services you want, or bring your own tools. We personally love Athena/Trino, PySpark, dbt, and Dagster.

mytiki.com has guides on connecting to clean rooms from common data tooling. If you can’t find what you’re looking for, just Google/ChatGPT Iceberg + <tool>. The data world loves Iceberg.
What data is available?
Our current panel focuses on financial transaction data representing roughly 4 million US consumers and 7 billion records, with over 5 years of historical context.
Purchase Transactions containing information such as the date, amount, merchant, type, and location — view complete taxonomy.
Product Receipts containing information such as the UPC code, quantity, merchant, price, and item description — view complete taxonomy.
Consumer Demographics containing information such as age, race, gender, income band, and location — view complete taxonomy.
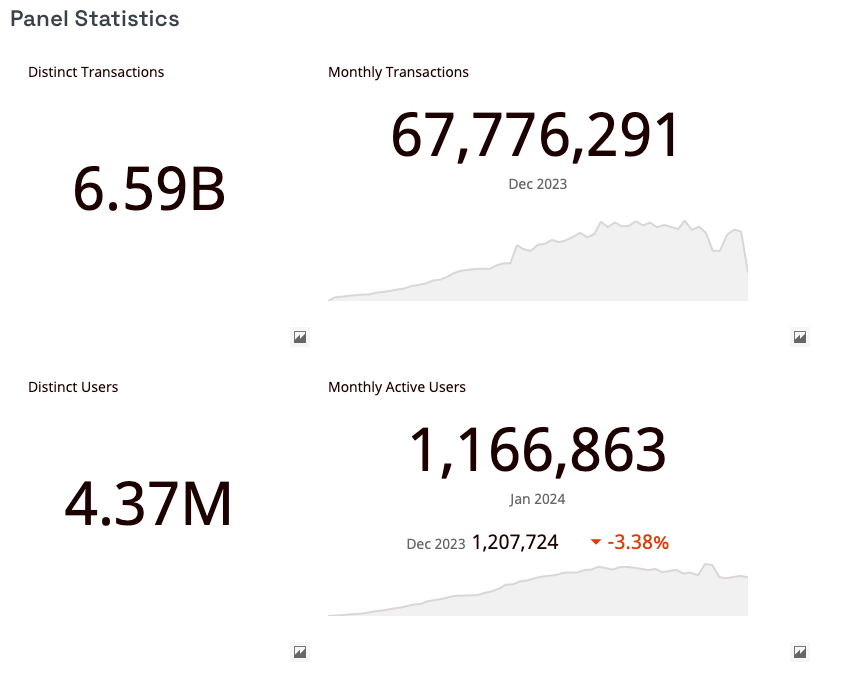
Coverage
At mytiki.com/docs/datasets you will find a number of live analytic dashboards to explore at a high-level the coverage and contents of the datasets. For example, the panel exhibits a pretty uniform distribution in transactions amongst the continental United States, represents predominantly Millennial and Get Z consumers, and spans over 1 million merchants.



To recap, all consumer data is legally licensed directly from end users with a complete audit trail —your compliance team will love us. We provide consumer data on-demand, in a modern structure that integrates seamlessly with your data infrastructure.
We’ve been building for a few years and have now begun onboarding our first data providers and customers the last few months. As we rapidly scale our panel size, there are free trial credits for eval floating around ;).
Stay tuned.
TREMENDA IDEA....ME GUSTA, SALUDOS DESDE VENEZUELA